۱۸ دستور نظارت بر پهنای باند شبکه در سرورهای لینوکس
در این مقاله قصد داریم تا به صورت کامل به بررسی ۱۸ دستور برای نظارت بر پهنای باند شبکه در سرورهای لینوکسی بپردازیم و در مورد نظارت بر شبکههای لینوکسی با شما عزیزان در زاگریو صحبت کنیم.
نظارت بر شبکههای لینوکسی:
این مقاله به برخی از ابزارهای خط فرمان لینوکس اشاره میکند که میتوان برای مانیتورینگ مصرف شبکه از آنها استفاده کرد. این ابزارها جریان ترافیک را از طریق رابطهای شبکه نظارت میکنند و سرعت داده هایی که در حال انتقال هستند را اندازهگیری میکنند. ترافیک ورودی و خروجی به طور جداگانه نمایش داده میشود.
برخی از دستورات پهنای باند استفاده شده را برای فرآیندهای تکی نمایش میدهد. با این دستورات به آسانی میتوان فرآیندهایی که بیش از حد از پهنای باند شبکه استفاده میکنند را شناسایی کرد.
این ابزارها مکانیزمهای مختلفی برای تولید گزارش ترافیک دارند. برخی از این ابزارها مانند nload فایل “proc/net/dev” برای دریافت آمار ترافیک میخوانند درحالیکه برخی دیگر از کتابخانه pcap برای دریافت همه بستهها استفاده میکنند و سپس حجم کلی بار ترافیکی تخیمنزده شده را محاسبه میکنند.
در اینجا لیستی از دستورات را داریم که بر اساس ویژگیهایشان مرتب شدهاند.
- Bandwidth به صورت کلی: nload ,bmon ,slurm ,bwm-ng ,cbm ,speedometer ,netload
- پهنای باند به صورت کلی (خروجی به صورت دستهای): vnstat ,ifstat ,dstat ,collectl
- Bandwidth در هر اتصال سوکت: iftop ,iptraf ,tcptrack ,pktstat ,netwatch ,trafshow
- پهنای باند برای هر فرآیند: nethogs
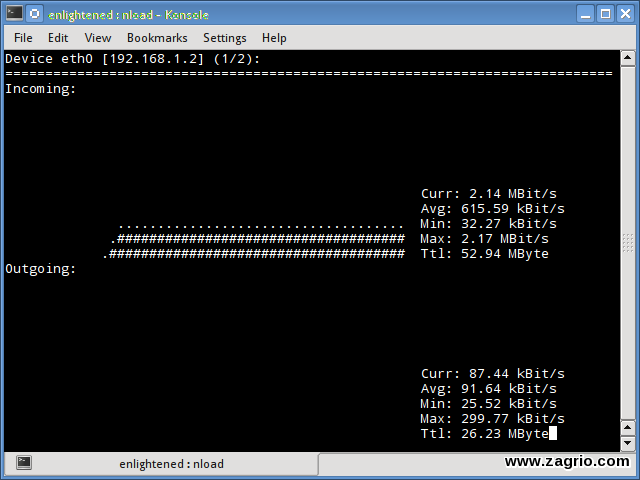
1. Nload
Nload یک ابزار خط فرمان است که اجازه میدهد کابران ترافیک ورودی و خروجی خود را به طور جداگانه نظارت (مانیتور) کنند. همچنین یک گراف برای شما طراحی میکند که همان موارد را نشان میدهد و مقیاس آن قابل تنظیم است. استفاده آن راحت و آسان است و گزینههای بسیاری را پشتیبانی نمیکند.
بنابر این اگر شما فقط نیاز دارید که با یک نگاه سریع کل مصرف پهنای باند را بدون جزئیات فرآیندهای فردی مشاهده کنید Nload میتواند مفید باشد.
$ nload
نصب Nload:
Fedora و Ubuntu ابزار را در مخازن پیشفرض دارند، کاربران لینوکس نیاز دارند که از مخازن Epel آنرا دریافت کنند.
# fedora or centos
$ yum install nload -y
# ubuntu/debian
$ sudo apt-get install nload
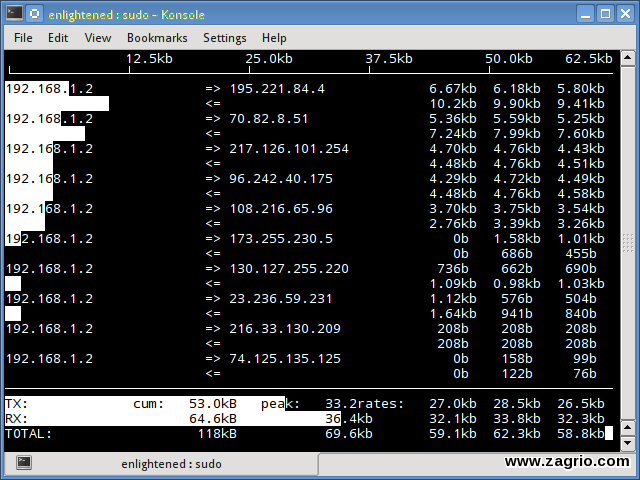
2. Iftop
Iftop جریان داده را از طریق ارتباطهای سوکتهای فردی اندازهگیری میکند، و در این مورد به شیوهای متفاوت با Nload عمل میکند. ایف تاپ با استفاده از توابع کتابخانهای pcap بستههای درحال حرکت در داخل و خارج از آداپتور شبکه را میگیرد و سپس از مجموع تعداد و اندازه آنها کل پهنای باند تحت استفاده را مشخص میکند.
اگرچه iftop پهنای باند استفاده شده را برای ارتباطات فردی گزارش میدهد، اما نام/شناسه فرآیندی که شامل ارتباط یک سوکت خاص است را نمیتواند گزارش دهد. وقتی که برپایه تابع pcap کار میکند iftop توانایی فیلتر کردن و ارائه گزارش بر اساس سرورهایی که به آن متصل هستند را داراست.
$ sudo iftop -n
گزینه n مانع از این میشود که iftop ip را به صورت hostname یا بالعکس بگیرد که همین مورد باعث ایجاد ترافیک شبکه اضافی میشود.
نصب iftop:
کاربران Ubuntu/Debian/Fedora آنرا از مخازن پیشفرض دریافت کنند و کاربران لینوکس از Epel می توانند iftop را دریافت کنند.
# fedora or centos
yum install iftop -y
# ubuntu or debian
$ sudo apt-get install iftop
3. Iptraf
Iptraf یک مانیتورینگ رنگارنگ و تعاملی از شبکه IP است، که اتصالات فردی و مقدار داده درحال جریان بین دو میزبان را نشان میدهد. در اینجا یک تصویر از این دستور میبینید.
$ sudo iptraf
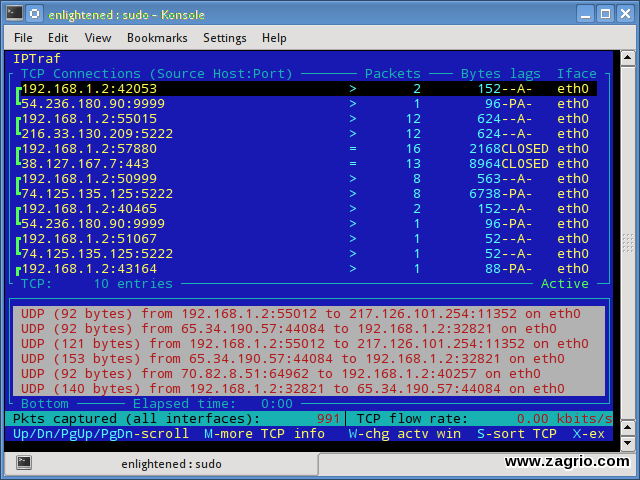
نصب iptraf:
# Centos (base repo)
$ yum install iptraf
# fedora or centos (with epel)
$ yum install iptraf-ng -y
# ubuntu or debian
$ sudo apt-get install iptraf iptraf-ng
4. Nethogs
Nethogs یک ابزار کوچک از ‘net top’ است که پهنای باند مصرف شده توسط فرآیندهای فردی را نشان میدهد و آنها را در لیستی مرتب میکند که فرآیندهای فشردهتر در بالای این لیست قرار میگیرند. در صورت افزایش ناگهانی پهنای باند، سریع Nethogs را باز کنید و فرآیندهای مسئول را پیدا کنید. Nethogs کاربر، PID و مسیر برنامه را گزارش میدهد.
$ sudo nethogs
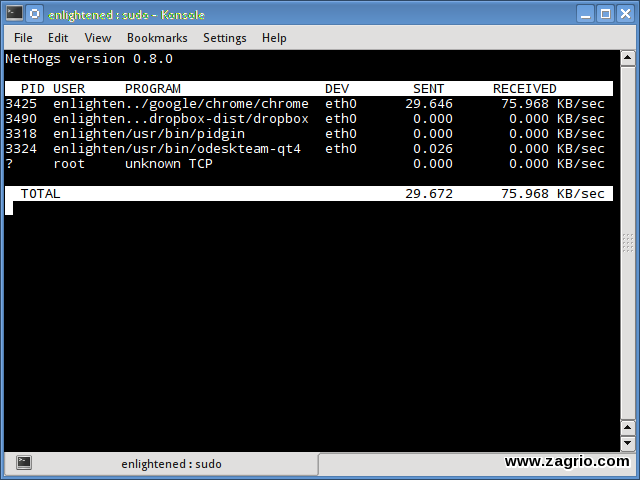
نصب Nethogs:
کاربران Ubuntu/Debian/Fedora این ابزار را از مخازن پیشفرض دریافت کنند و کاربران لینوکس نیاز به Epel دارند.
# ubuntu or debian (default repos)
$ sudo apt-get install nethogs
# fedora or centos (from epel)
$ sudo yum install nethogs -y
5. Bmon
(Bmon (Bandwith monitor یک ابزار مشابه با Nload است که بار ترافیکی بیش از حد در تمامی رابطهای شبکه به روی سیتسم را نشان میدهد. خروجی یک گراف و یک بخش از جزئیات یکسان بستههاست.
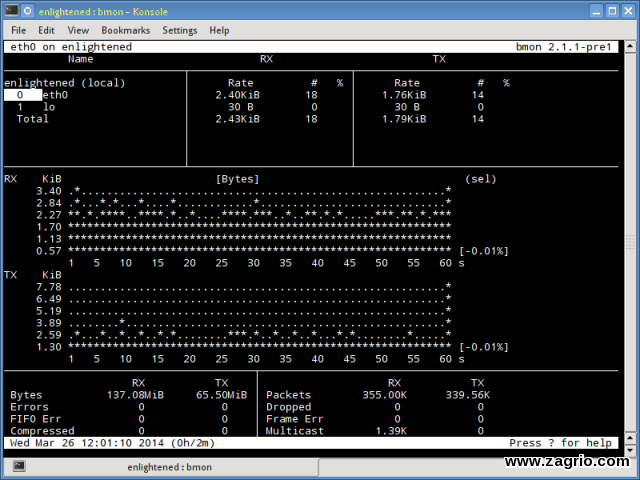
نصب Bmon:
کاربران Ubuntu/Debian/Fedora این ابزار را از مخازن پیشفرض نصب کنند و کاربران لینوکس نیاز دارند که repoforge را تنظیم کنند زیرا Epel در دسترس نیست.
# ubuntu or debian
$ sudo apt-get install bmon
# fedora or centos (from repoforge)
$ sudo yum install bmon
Bmon گزینههای بسیاری را پشتیبانی میکند و قادر است گزارشهایی با فرمت html تولید کند. Man page را برای کسب اطلاعات بیشتر در این مورد بررسی کنید.
6. Slurm
Slurm هنوز یکی از ابزارهای نظارت بار شبکه است که آمار دستگاهها را همراه با نمودار ASCII نمایش میدهد. این ابزار از سه سبک مختلف نمودارها پشتیبانی میکند که هر کدام میتوانند با استفاده از کلیدهای L C و S فعال شوند. Slurm هیچ اطلاعات بیشتری در مورد بار شبکه نشان نمیدهد.
$ slurm -s -i eth0
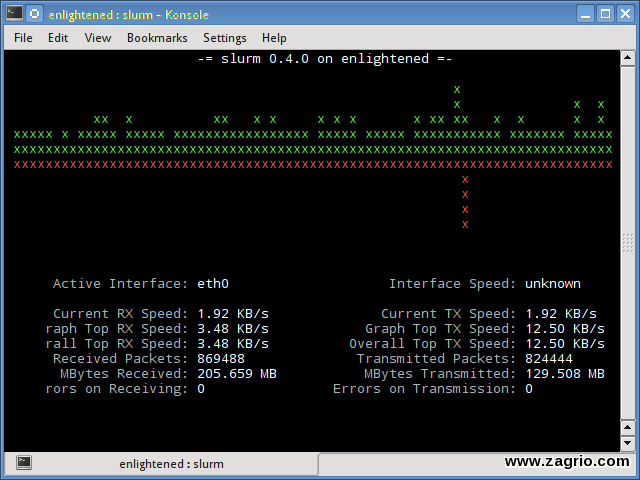
نصب slurm:
# debian or ubuntu
$ sudo apt-get install slurm
# fedora or centos
$ sudo yum install slurm -y
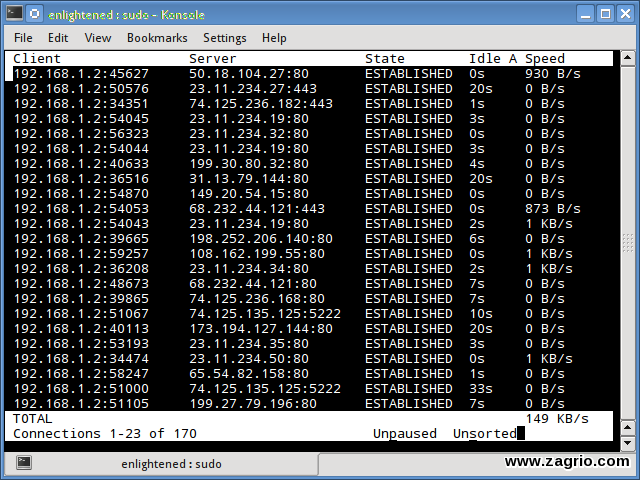
7. Tcptrack | پهنای باند
Tcptrack شبیه iftop است و با استفاده از توابع کتابخانه pcap بستهها را تصرف میکند و آمارهای مختلف مانند پهنای باند استفاده شده در هر اتصال را محاسبه میکند. این ابزار همچنین فیلتر استاندارد pcap را پشتیبانی میکند که برای مانیتور اتصالات خاص میتواند مورد استفاده قرار گیرد.
$ slurm -s -i eth0
نصب tctrack:
کاربران Ubuntu/Debian/Fedora این ابزار را از مخازن پیشفرض نصب کنند و کاربران لینوکس نیاز دارند که repoforge را تنظیم کنند زیرا Epel در دسترس نیست.
# ubuntu, debian
$ sudo apt-get install tcptrack
# fedora, centos (from repoforge repository)
$ sudo yum install tcptrack
8. Vnstat
Vnstat با بسیاری از ابزارهای دیگر کمی متفاوت است. این ابزار یک پس زمینه service/daemon را اجرا میکند و اندازه دادههای انتقال یافته را در تمام زمانها نگهداری میکند. سپس میتواند برای تولید گزارش از تاریخ استفاده شبکه از این اطلاعات استفاده کند.
$ service vnstat status
* vnStat daemon is running
اجرای Vnstat بدون هیچ گزینهای به سادگی مقدار کل انتقال اطلاعات را نشان میدهد از تاریخی که daemon در حال اجراست.
$ vnstat
Database updated: Mon Mar 17 15:26:59 2014
eth0 since 06/12/13
rx: 135.14 GiB tx: 35.76 GiB total: 170.90 GiB
monthly
rx | tx | total | avg. rate
————————+————-+————-+—————
Feb ’14 8.19 GiB | 2.08 GiB | 10.27 GiB | 35.60 kbit/s
Mar ’14 4.98 GiB | 1.52 GiB | 6.50 GiB | 37.93 kbit/s
————————+————-+————-+—————
estimated 9.28 GiB | 2.83 GiB | 12.11 GiB |
daily
rx | tx | total | avg. rate
————————+————-+————-+—————
yesterday 236.11 MiB | 98.61 MiB | 334.72 MiB | 31.74 kbit/s
today 128.55 MiB | 41.00 MiB | 169.56 MiB | 24.97 kbit/s
————————+————-+————-+—————
estimated 199 MiB | 63 MiB | 262 MiB |
برای نظارت بر استفاده از پهنای باند در زمان واقعی از گزینه ‘-l ‘ (live mode) استفاده کنید. این مورد کل پهنای باند استفاده شده توسط اطلاعات ورودی و خروجی نشان میدهد اما به شیوهای بسیار دقیق بدون هیچگونه اطلاعات ورودی در مورد جزئیات داخلی اتصالات یا فرآیندهای آن.
$ vnstat -l -i eth0
Monitoring eth0… (press CTRL-C to stop)
rx: 12 kbit/s 10 p/s tx: 12 kbit/s 11 p/s
Vnstat بیشتر شبیه ابزارهای گزارشگیری است که گزارش تاریخی است چه میزان از پهنای باند به صورت روزانه یا در ماه گذشته استفاده شده است. این صرفا یک ابزار برای نظارت بر شبکه در زمان واقعی نیست.
Vnstat گزینه های بسیاری را پشتیبانی میکند. جزئیات را در این مورد میتوانید در man page پیدا کنید.
نصب Vnstat:
# ubuntu or debian
$ sudo apt-get install vnstat
# fedora or centos (from epel)
$ sudo yum install vnstat
9. Bwm-ng
(Bwm-ng (Bandwidth Monitor Next Generation یکی دیگر از ابزارهای بسیار ساده برای مانیتور بار شبکه در زمان واقعی است که خلاصهای از سرعتی که داده در داخل و خارج شبکه موجود بر روی سیستم منتقل میشود را گزارش میدهد.
$ bwm-ng
bwm-ng v0.6 (probing every 0.500s), press ‘h’ for help
input: /proc/net/dev type: rate
/ iface Rx Tx T
ot==========================================================================
== eth0: 0.53 KB/s 1.31 KB/s 1.84
KB lo: 0.00 KB/s 0.00 KB/s 0.00
KB————————————————————————–
— total: 0.53 KB/s 1.31 KB/s 1.84
KB/s
اگر کنسول به حد کافی بزرگ باشد bwm-ng میتواند نمودار میلهای را برای ترافیک استفاده شده در حالت خروجی نشان دهد.
$ bwm-ng -o curses2
نصب Bwm-NG:
برای CentOS میتوان Bwm-NG را از Epel نصب کرد.
# ubuntu or debian
$ sudo apt-get install bwm-ng
# fedora or centos (from epel)
$ sudo apt-get install bwm-ng
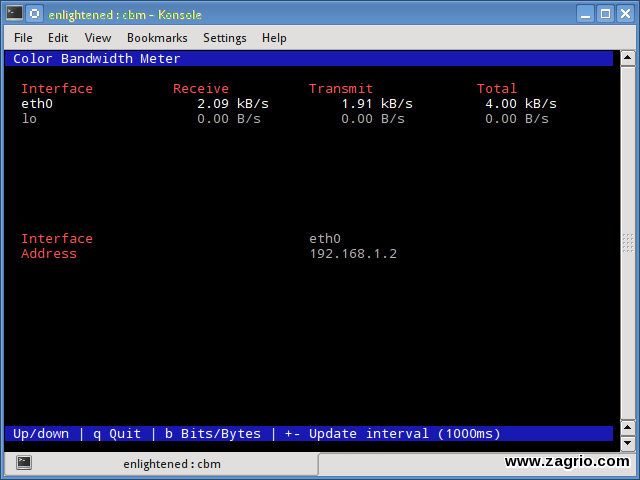
10. cbm – Color Bandwidth Meter
کمی نظارت بر پهنای باند که حجم ترافیک را از طریق رابطهای شبکه نشان میدهد ساده است. بدون هیچ گزینه اضافی فقط ترافیک و بهروزرسانی در زمان واقعی نشان داده میشود.
$ sudo apt-get install cbm
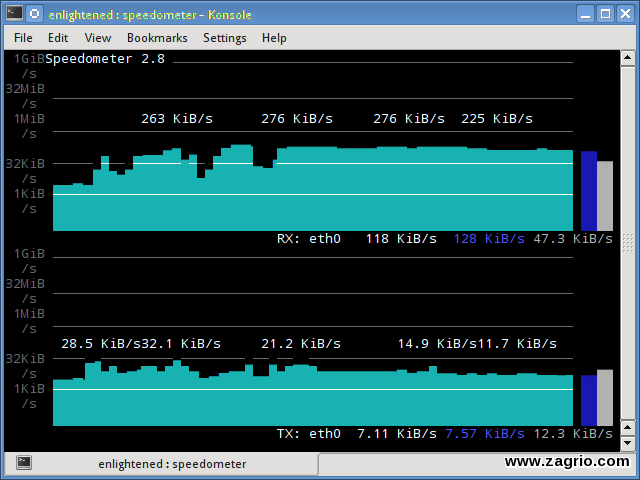
11. speedometer
یکی دیگراز ابزارهای ساده و کوجک که نمودارهایی از ترافیک ورودی و خروجی که از طریق یک رابط داده شده است را به خوبی ترسیم می کند.
$ speedometer -r eth0 -t eth0
نصب speedometer:
# ubuntu or debian users
$ sudo apt-get install speedometer
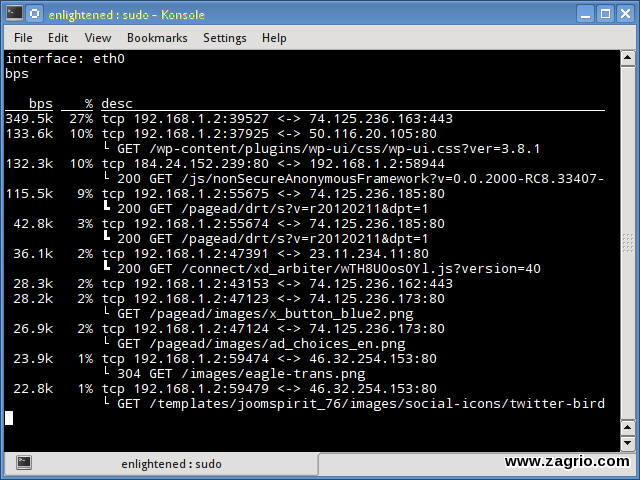
12. Pktstat
Pktstat تمامی اتصالات فعال در زمان واقعی و سرعتی که داده از طریق آنها منتقل میشوند را نشان میدهد. همچنین نوع اتصالات مانند tcp یا udp و جزئیات در مورد درخواستهای http نشان میدهد.
$ sudo pktstat -i eth0 –nt
$ sudo apt-get install pktstat
13. Netwatch
Netwatch قسمتی از مجموعه ابزار netdiag است و ارتباطهای بین local host و دیگر remote host ها و سرعت انتقال داده در هر ارتباط را نشان میدهد.
$ sudo netwatch -e eth0 -nt
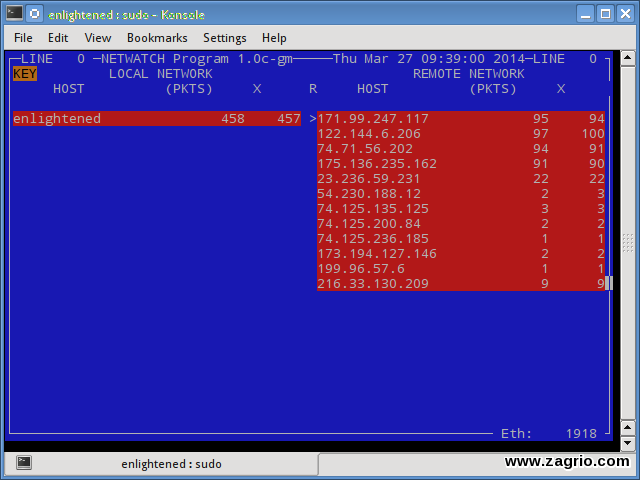
$ sudo apt-get install netdiag
14. Trafshow
Trafshow مانند netwatch و pktstat ارتباطات فعال فعلی، پروتکلهایشان و سرعت انتقال داده در هر کدام از این ارتباطات را گزارش میدهد. این ابزار میتواند با استفاده از فیلترهای نوع pcap ارتباطات را فیلتر کند.
$ sudo trafshow -i eth0 tcp
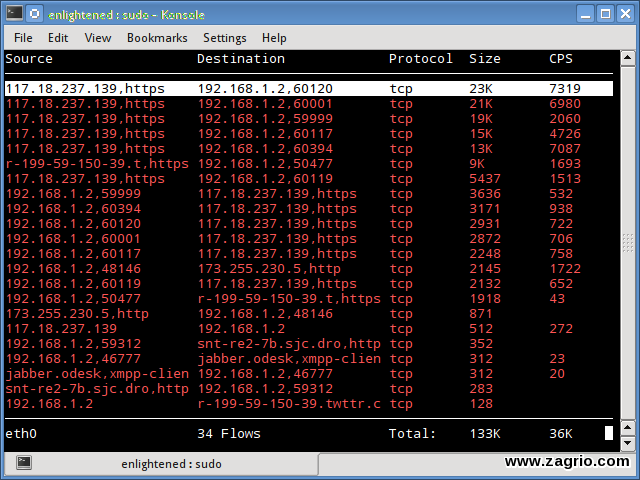
$ sudo apt-get install netdiag
فقط اتصالات tcp را نظارت میکند.
15. Netload
دستور Netload فقط گزارش کوچکی از بار ترافیک فعلی شبکه و تعداد کل بایتهایی که از زمان شروع برنامه منتقل شده است را نشان میدهد. هیچ ویژگی بیشتری وجود ندارد. این ابزار بخشی از netdiag است.
$ netload eth0
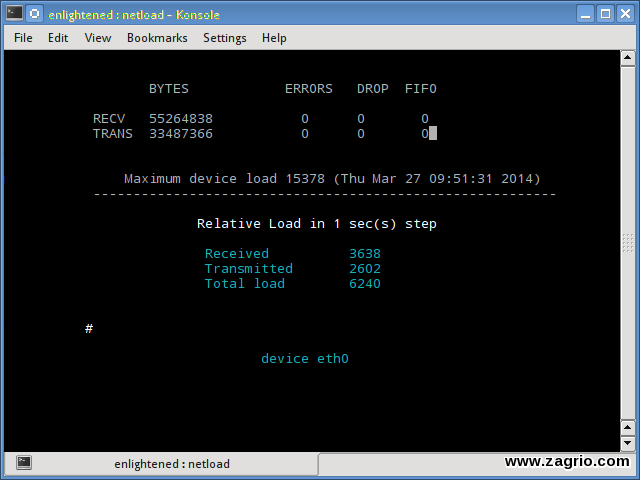
$ sudo apt-get install netdiag
16. Ifstat
Instat پهنای باند شبکه را در حالت دستهای گزارش میدهد. خروجی در یک فرمتی است که برای ورودی و تجزیه با استفاده از دیگر برنامهها آسان است.
$ ifstat -t -i eth0 0.5
Time eth0
HH:MM:SS KB/s in KB/s out
۰۹:۵۹:۲۱ ۲٫۶۲ ۲٫۸۰
۰۹:۵۹:۲۲ ۲٫۱۰ ۱٫۷۸
۰۹:۵۹:۲۲ ۲٫۶۷ ۱٫۸۴
۰۹:۵۹:۲۳ ۲٫۰۶ ۱٫۹۸
۰۹:۵۹:۲۳ ۱٫۷۳ ۱٫۷۹
نصب ifstat:
کاربران Ubuntu/Debian/Fedora این ابزار را در مخازن پیشفرض دارند و کاربران لینوکس نیاز دارند که repoforge را تنظیم کنند زیرا Epel در دسترس نیست.
# ubuntu, debian
$ sudo apt-get install ifstat
# fedora, centos (Repoforge)
$ sudo yum install ifstat
17. dstat
dstst یک ابزار همهکاره است که میتواند آمار سیستمهای مختلف را مانیتور کند و آنها را در یک حالت دستهای یا ورود دادهها به سیستم csv و یا مشابه فایل گزارش کند.
$ dstat -nt
-net/total- —-system—-
recv send| time
۰ ۰ |۲۳-۰۳ ۱۰:۲۷:۱۳
۱۷۳۸B 1810B|23-03 10:27:14
۲۹۳۷B 2610B|23-03 10:27:15
۲۳۱۹B 2232B|23-03 10:27:16
۲۷۳۸B 2508B|23-03 10:27:17
نصب dstat:
$ sudo apt-get install dstat
18. Collect
Collect آمار سیستمهایی را که در یک سبک است را نشان میدهد که شبیه به dstat است و مانند dstat آمار را درمورد منابع مختلف سیستمهای مختلف مانند cpu ،memory ،network و غیره را جمعآوری میکند. در اینجا یک مثال ساده از نحوه استفاده آن برای گزارش گرفتن از usage/bandwidth آمده است.
$ collectl -sn -oT -i0.5
waiting for 0.5 second sample…
# <———-Network———->
#Time KBIn PktIn KBOut PktOut
۱۰:۳۲:۰۱ ۴۰ ۵۸ ۴۳ ۶۶
۱۰:۳۲:۰۱ ۲۷ ۵۸ ۳ ۳۲
۱۰:۳۲:۰۲ ۳ ۲۸ ۹ ۴۴
۱۰:۳۲:۰۲ ۵ ۴۲ ۹۶ ۹۶
۱۰:۳۲:۰۳ ۵ ۴۸ ۳ ۲۸
نصب Collect:
# Ubuntu/Debian users
$ sudo apt-get install collectl
#Fedora
$ sudo yum install collectl
خلاصه:
این دستورات چند فرمان سودمند بودند که به سرعت میتوانید پهنای باند شبکه را بر روی سرور لینوکس خود بررسی کنید. برای اجرای این دستورات نیاز است که کاربر با استفاده از SSH به سرور خود log in کند. ابزارهای مانیتورینگ مبتنی بر وب میتوانند برای همین کار استفاده شوند.
Ntop و Darkstat برخی از ابزارهای مانیتورینگ مبتنی بر وب برای لینوکس هستند. صرفنظر از این دروغ که ابزارهای مانیتورینگ در سطح سازمانی مانند Nagios که نه تنها یک میزبان از ویژگیها برای مانیتور و نظارت بر شبکه فراهم میکنند بلکه کل زیر ساخت را هم دربرمیگیرند.