2.9kviews
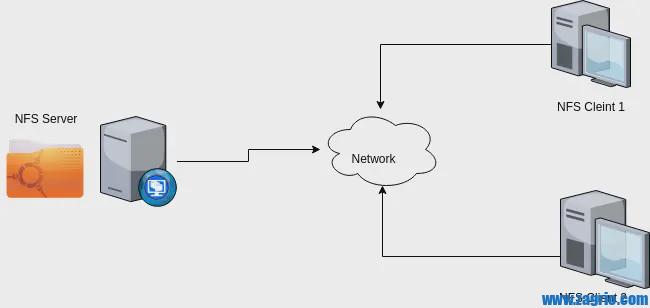
در این مقاله چگونگی راهاندازی یک سرور NFS و یک کلاینت NFS روی یک CentOS 7.2 آموزش داده میشود. از طریق NFS یک کلاینت میتواند به صورت Remote روی یک سرور NFS دسترسی (خواندن و نوشتن ) داشته باشد به صورتیکه فایلهایی که بر روی سرور هستند انگار که روی کامپیوتر خود شخص قرار دارند. ما به عنوان پایه از یک سرور CentOS 7.2 minimal برای نصب و راهاندازی استفاده میکنیم.
۱- نکات مقدماتی سرور و کلاینت NFS:
ما در اینجا از دو سیستم CentOS استفاده میکنیم:
• NFS Server: server.example.com, IP address: 192.168.1.100
• NFS Client: client.example.com, IP address: 192.168.1.101
در این آموزش از یک ویرایشگر نانو برای ویرایش فایلهای پیکربندی استفاده میکنیم. نانو میتواند با استفاده از دستور زیر نصب شود:
yum -y install nano
۲- پیکربندی فایروال:
توصیه میکنیم که یک فایروال نصب شده داشته باشید. اگر فایروالی نصب ندارید و میخواهید از فایروال استفاده کنید با استفاده از دستور زیر میتوانید آنرا نصب کنید:
yum -y install firewalld
شروع فایروال و فعال شدن آن در زمان بوت آغاز میشود.
systemctl start firewalld.service
systemctl enable firewalld.service
در ادامه بعد از باز کردن SSH و پورتهای NFS مطمئن شوید که از طریق SSH قادر خواهید بود که به سرور متصل شوید برای انجام اهداف مدیریتی توسط NFS و کلاینهای NFS.
firewall-cmd --permanent --zone=public --add-service=ssh
firewall-cmd --permanent --zone=public --add-service=nfs
firewall-cmd --reload
۳- نصب NFS:
سرور:
برای سرور NFS دستور زیر را اجرا می کنیم:
yum -y install nfs-utils
سپس برای فعالسازی و شروع سرویسهای NFS دستورات زیر را اجرا کنید:
systemctl enable nfs-server.service
systemctl start nfs-server.service
کلاینت:
بر روی کلاینتها میتوانیم NFS را مطابق زیر نصب کنیم (در واقع بر روی همان سرور است):
yum install nfs-utils
۴- مسیرهای خروجی بر روی سرور و کلاینت NFS:
سرور:
ما میخواهیم دایرکتوری home/ و var/nfs/ برای کلاینتها در دسترس باشد. بنابراین باید آنها را بر روی سرور Export کنیم.
وقتی که یک کلاینت به یک NFS share دسترسی داشته باشد به طور معمول به عنوان کاربر nfsnobody است. معمولا دایرکتوری home/ متعلق به nfsnobody نیست (و من توصیه میکنم که مالکیت آنرا به nfsnobody تغییر ندهید) و چون ما میخواهیم در home/ بخوانیم و بنویسیم پس باید دسترسی به NFS share به عنوان root ایجاد شود (اگر home فقط خواندنی باشد نیازی به انجام این کار نیست). دایرکتوری var/nfs/ وجود ندارد، بنابراین ما میتوانیم آن را ایجاد کنیم و مالکیت آن را به کاربر و nfsnobody تغییر دهیم.
mkdir /var/nfs
chown nfsnobody:nfsnobody /var/nfs
chmod 755 /var/nfs
اکنون ما باید /etc/exports که NFS shares خود را export میکنیم را اصلاح کنیم. ما home/ و var/nfs/ را به عنوان NFX share مشخص میکنیم و دسترسیhome/ را به عنوان root ایجاد میکنیم.
man 5 exports
nano /etc/exports
/home 192.168.1.101(rw,sync,no_root_squash,no_subtree_check)
/var/nfs 192.168.1.101(rw,sync,no_subtree_check)
گزینه no_root_squash باعث می شود که home/ به عنوان ریشه در دسترس باشد.
هر زمان که ما /etc/exports را اصلاح کردیم باید دستور زیر را اجرا کنیم:
exportfs –a
پس از آن،ایجاد تغییرات موثر است.
۵- نصب و راهاندازی NFS Shares روی سرور و کلاینت NFS:
کلاینت:
در ابتدا ما یک دایرکتوریهایی را ایجاد می کنیم که می خواهیم NFS shares در آن قرار بگیرند مانند:
mkdir -p /mnt/nfs/home
mkdir -p /mnt/nfs/var/nfs
در ادامه میتوانیم به صورت زیر آنها را مقدار دهیم:
mount 192.168.1.100:/home /mnt/nfs/home
mount 192.168.1.100:/var/nfs /mnt/nfs/var/nfs
اکنون باید دو فایل NFS shares در خروجی داشته باشید:
[root@client ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 28G 1.7G 26G 7% /
devtmpfs 909M 0 909M 0% /dev
tmpfs 919M 0 919M 0% /dev/shm
tmpfs 919M 8.6M 910M 1% /run
tmpfs 919M 0 919M 0% /sys/fs/cgroup
/dev/sda1 497M 208M 290M 42% /boot
tmpfs 184M 0 184M 0% /run/user/0
۱۹۲٫۱۶۸٫۱٫۱۰۰:/home 28G 1.2G 27G 5% /mnt/nfs/home
۱۹۲٫۱۶۸٫۱٫۱۰۰:/var/nfs 28G 1.2G 27G 5% /mnt/nfs/var/nfs
و
mount
mount[root@client ~]# mount
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime,seclabel)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
devtmpfs on /dev type devtmpfs (rw,nosuid,seclabel,size=930320k,nr_inodes=232580,mode=755)
securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime)
tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev,seclabel)
devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,seclabel,gid=5,mode=620,ptmxmode=000)
tmpfs on /run type tmpfs (rw,nosuid,nodev,seclabel,mode=755)
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,seclabel,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
pstore on /sys/fs/pstore type pstore (rw,nosuid,nodev,noexec,relatime)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/net_cls type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
configfs on /sys/kernel/config type configfs (rw,relatime)
/dev/mapper/centos-root on / type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
selinuxfs on /sys/fs/selinux type selinuxfs (rw,relatime)
systemd-1 on /proc/sys/fs/binfmt_misc type autofs (rw,relatime,fd=25,pgrp=1,timeout=300,minproto=5,maxproto=5,direct)
mqueue on /dev/mqueue type mqueue (rw,relatime,seclabel)
debugfs on /sys/kernel/debug type debugfs (rw,relatime)
hugetlbfs on /dev/hugepages type hugetlbfs (rw,relatime,seclabel)
sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw,relatime)
nfsd on /proc/fs/nfsd type nfsd (rw,relatime)
/dev/sda1 on /boot type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
tmpfs on /run/user/0 type tmpfs (rw,nosuid,nodev,relatime,seclabel,size=188060k,mode=700)
۱۹۲٫۱۶۸٫۱٫۱۰۰:/home on /mnt/nfs/home type nfs4 (rw,relatime,vers=4.0,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,port=0,timeo=600,retrans=2,sec=sys,clientaddr=192.168.1.101,local_lock=none,addr=192.168.1.100)
۱۹۲٫۱۶۸٫۱٫۱۰۰:/var/nfs on /mnt/nfs/var/nfs type nfs4 (rw,relatime,vers=4.0,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,port=0,timeo=600,retrans=2,sec=sys,clientaddr=192.168.1.101,local_lock=none,addr=192.168.1.100)-
۶- تست کردن سرور و کلاینت NFS:
اکنون شما میتوانید روی کلاینت یک فایل تست در NFS shares ایجاد کنید:
کلاینت:
touch /mnt/nfs/home/test.txt
touch /mnt/nfs/var/nfs/test.txt
اکنون به سرور بروید و بررسی کنید که آیا هر دو فایل تست را میتوانید مشاهده کنید:
سرور:
ls -l /home/
[root@server1 ~]# ls -l /home/
total 0
drwx------. 2 administrator administrator 59 Jun 21 16:13 administrator
-rw-r--r--. 1 root root 0 Jun 29 13:07 test.txt
ls -l /var/nfs
[root@server1 ~]# ls -l /var/nfs
total 0
-rw-r--r--. 1 nfsnobody nfsnobody 0 Jun 29 13:07 test.txt
(لطفا به مالکیتهای مختلف فایلهای تست توجه داشته باشید. home NFS share/ بعنوان ریشه (root) دیده میشود. بنابراین /home/test.txt متعلق به ریشه است. /var/nfs share به عنوان nobody/65534 دیده میشود بنابراین /var/nfs/test.txt متعلق به nobody است).
۷- نصب و راهاندازی NFS Shares در زمان بوت:
به جای نصب و راهاندازی NFS Shares به صورت دستی روی سرور، شما میتوانید /etc/fstab را تغییر دهید بهصورتیکه NFS shares به طور خودکار هنگامیکه کلاینت بوت میشود نصب و راهاندازی شود.
کلاینت:
etc/fstab/ را باز کنید و خطوط زیر را دنبال کنید:
nano /etc/fstab
[...]
۱۹۲٫۱۶۸٫۱٫۱۰۰:/home /mnt/nfs/home nfs rw,sync,hard,intr 0 0
۱۹۲٫۱۶۸٫۱٫۱۰۰:/var/nfs /mnt/nfs/var/nfs nfs rw,sync,hard,intr 0 0
به جای rw,sync,hard,intr شما میتوانید گزینههای مختلفی استفاده کنید. برای کسب اطلاعات بیشتر در مورد گزینههای موجود نگاهی بیندازید به:
man nfs
برای اینکه تست کنید که فایل اصلاح شده /etc/fstab کار میکند، کلاینت را reboot کنید:
Reboot
پس از راهاندازی مجدد سیستم، شما باید دو NFS shares در خروجی داشته باشید:
df –h
[root@client ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 28G 1.7G 26G 7% /
devtmpfs 909M 0 909M 0% /dev
tmpfs 919M 0 919M 0% /dev/shm
tmpfs 919M 8.6M 910M 1% /run
tmpfs 919M 0 919M 0% /sys/fs/cgroup
/dev/sda1 497M 208M 290M 42% /boot
tmpfs 184M 0 184M 0% /run/user/0
۱۹۲٫۱۶۸٫۱٫۱۰۰:/home 28G 1.2G 27G 5% /mnt/nfs/home
۱۹۲٫۱۶۸٫۱٫۱۰۰:/var/nfs 28G 1.2G 27G 5% /mnt/nfs/var/nfs
و
mount
[root@client ~]# mount
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime,seclabel)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
devtmpfs on /dev type devtmpfs (rw,nosuid,seclabel,size=930320k,nr_inodes=232580,mode=755)
securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime)
tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev,seclabel)
devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,seclabel,gid=5,mode=620,ptmxmode=000)
tmpfs on /run type tmpfs (rw,nosuid,nodev,seclabel,mode=755)
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,seclabel,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
pstore on /sys/fs/pstore type pstore (rw,nosuid,nodev,noexec,relatime)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/net_cls type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
configfs on /sys/kernel/config type configfs (rw,relatime)
/dev/mapper/centos-root on / type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
selinuxfs on /sys/fs/selinux type selinuxfs (rw,relatime)
systemd-1 on /proc/sys/fs/binfmt_misc type autofs (rw,relatime,fd=25,pgrp=1,timeout=300,minproto=5,maxproto=5,direct)
mqueue on /dev/mqueue type mqueue (rw,relatime,seclabel)
debugfs on /sys/kernel/debug type debugfs (rw,relatime)
hugetlbfs on /dev/hugepages type hugetlbfs (rw,relatime,seclabel)
sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw,relatime)
nfsd on /proc/fs/nfsd type nfsd (rw,relatime)
/dev/sda1 on /boot type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
tmpfs on /run/user/0 type tmpfs (rw,nosuid,nodev,relatime,seclabel,size=188060k,mode=700)
۱۹۲٫۱۶۸٫۱٫۱۰۰:/home on /mnt/nfs/home type nfs4 (rw,relatime,vers=4.0,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,port=0,timeo=600,retrans=2,sec=sys,clientaddr=192.168.1.101,local_lock=none,addr=192.168.1.100)
۱۹۲٫۱۶۸٫۱٫۱۰۰:/var/nfs on /mnt/nfs/var/nfs type nfs4 (rw,relatime,vers=4.0,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,port=0,timeo=600,retrans=2,sec=sys,clientaddr=192.168.1.101,local_lock=none,addr=192.168.1.100)
۸- لینکهای سرور و کلاینت NFS:
Linux NFS: http://nfs.sourceforge.net/
CentOS: http://www.centos.org/